学习率
学习率太大或太小的问题:

降低学习率的准则:
- 曲线越陡, 步伐越大
- 曲线越平, 步伐越小
训练集 验证集 测试集
训练集用来训练模型, 验证集用来验证模型的准确性(需要通过验证集来不断调整参数), 测试集用来测试模型最后的准确性
测试集和验证集都会对模型产生影响
e.g.
400个数据点, 350个用来做训练比较合适
- (X_train, X_test) = X[50:], X[:50]
- (y_train, y_test) = y[50:], y[:50]
过拟合与欠拟合
当神经网络过于复杂, 或者模型迭代次数过多时, 就会出现过拟合; 反之, 则出现欠拟合

Early Stopping
通过早停机来防止过拟合

正则化
由于参数过多容易造成过拟合
通过惩罚大的权重来防止过拟合
- L1: $$ ERROR\quad FUNCTION = -\frac{1}{m}\sum_{i=1}^{m}(1 - y_i)ln(1 - \hat{y_i}) + y_iln(\hat{y_i}) + \lambda(|\omega_1|+…+|\omega_n|) $$
- L2: $$ ERROR\quad FUNCTION = -\frac{1}{m}\sum_{i=1}^{m}(1 - y_i)ln(1 - \hat{y_i}) + y_iln(\hat{y_i}) + \lambda({\omega_1}^2 + … + {\omega_n}^2) $$
Dropout
dropout是指在深度学习网络的训练过程中, 对于神经网络单元, 按照一定的概率将其暂时从网络中丢弃
注意是暂时, 对于随机梯度下降来说, 由于是随机丢弃, 故而每个mini-bath都在训练不同的网络
为什么dropout是有效的?(参考自https://blog.csdn.net/stdcoutzyx/article/details/49022443)
解释一:
大规模的神经网络有两个缺点:
- 费时
- 过拟合
为了解决过拟合问题, 一般会采用ensemble方法, 即训练多个模型做组合, 此时, 费事就称为一个大问题, 不经训练起来费时, 测试起来多个模型也费事; 总之, 几乎形成一个死锁
dropouot的出现很好地解决这个问题, 每次做完dropout, 相当于从原始的网络中找到一个更瘦的网络
因而, 对于一个有N个节点的神经网络, 有了dropout后, 就可以看做是\(2^n\)个模型的集合了, 但此时要训练的参数数目却是不变的, 这就解脱了费时的问题
解释二:
dropout强迫一个神经单元, 和随机挑选出来的其他神经单元共同工作, 达到好的效果; 消除减弱了神经元节点间的联合适应性, 增强了泛化能力
(更多dropout有效的原因及相关知识, 参考https://blog.csdn.net/stdcoutzyx/article/details/49022443)

在keras中应用dropout:
1 | model.add(Dense(32, activation='sigmoid')) |
其中, 0.2是每个神经元会被drop的概率(上面链接中的文章表明, 0.5可能最好, 原因是0.5的时候dropout随机生成的网络结构最多)
ReLU激活函数
sigmoid激活函数存在的问题:
梯度消失, 在反向传播的过程中, 当神经网络深度很大时, 随着求导次数的增加, 最终的导数值会很小, 接近于0, 从而难以对靠近输入层的参数做出改变

其他激活函数:


1 | # 激活函数 |
Random Restart
由于存在局部最优, 故通过随机开始迭代, 来尝试从不同的地方获得局部最优解, 从而比较获得全局最优解(不一定找得到, 则选择次优)
梯度下降优化
(以下内容参考自: https://blog.csdn.net/google19890102/article/details/69942970)
梯度下降法是最小化目标函数\(J(\theta)\)的一种方法, 其中, \(\theta\in R^d\)为模型参数, 梯度下降法用目标案数关于参数的梯度\(\nabla_\theta J(\theta)\)的反方向更新参数
学习率\(\eta\)或\(\alpha\)决定达到最小值或者局部最小值过程中所采用的步长的大小
即, 我们沿着目标函数的斜面下降的方向, 直到到达谷底
梯度下降法中有三种变形形式, 它们之间的区别为我们在计算目标函数的梯度时使用到多少数据
根据数据量的不同, 我们在参数更新的精度和更新过程中所需要的时间两个方面做出权衡
梯度下降法的变形形式
批梯度下降法
Vanilla梯度下降法, 又称为批梯度下降法(batch gradient descent), 在整个训练数据集上计算损失函数关于参数\(\theta\)的梯度:
$$ \theta = \theta - \eta \cdot \nabla_\theta J(\theta) $$
因为在执行每次更新时, 我们需要在整个数据集上计算所有梯度, 所以批梯度下降法的速度会很慢, 同时, 批梯度下降法无法处理超出内存容量限制的数据集, 同样也不能在线更新模型, 即在运行的过程中, 不能增加新的样本.
代码示例:
1 | for i in range(nb_epochs): |
对于凸误差函数, 批梯度下降法能够保证收敛到全局最小值, 对于非凸函数, 则收敛到一个局部最小值
随机梯度下降法
随机梯度下降法(stochastic gradient descent, SGD)根据每一条训练样本\(x^{(i)}\)和标签\(y^{(i)}\)更新参数:
$$ \theta = \theta - \eta \cdot \nabla_\theta J(\theta; x^{(i)}; y^{(i)}) $$
对于的大数据集, 因为批梯度下降法在每一个参数更新之前, 会对相似的样本计算梯度, 所以在计算过程中会有冗余; 而SGD在每一次更新中只执行一次, 从而消除了冗余; 因而, 通常SGD的运行速度更快, 同时, 可以用于在线学习; SGD以高方差频繁地更新, 导致目标函数出现如下图所示的剧烈波动
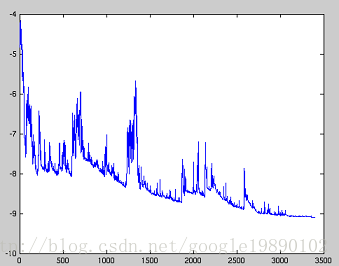
与梯度下降法的收敛会使得损失函数陷入局部最小相比, 由于SGD的波动性, 一方面, 波动性使得SGD可以跳到新的和潜在更好的局部最优; 另一方面, 这使得最终收敛到特定最小值的过程变得复杂, 因为SGD会一直持续波动; 然而, 已经证明当我们缓慢减小学习率, SGD与批梯度下降法具有相同的收敛行为, 对于非凸优化和凸优化, 可以分别收敛到局部最小值和全局最小值; 与批梯度下降的代码相比, SGD的代码片段仅仅是在对训练样本的遍历和利用每一条样本计算梯度的过程中增加一层循环; 在每一次循环中, 我们打乱训练样本
代码示例:
1 | for i in range(nb_epochs): |
小批量梯度下降法
小批量梯度下降法最终结合了上述两种方法的优点, 在每次更新时使用n个小批量训练样本:
$$ \theta = \theta - \eta \cdot \nabla_\theta J(\theta; x^{(i:i+n)}; y^{(i:i+n)}) $$
这种方法
- 减少参数更新的方差, 这样可以得到更加稳定的收敛结果
- 可以利用最新的深度学习库中高度优化的矩阵优化方法, 高效地求解每个小批量数据的梯度
通常, 小批量数据的大小在50到256之间, 也可以根据不同的应用有所变化; 当训练神经网络模型时, 小批量梯度下降法是典型的选择算法
代码示例:
1 | # 在大小为50的小批量数据上做迭代 |
挑战
虽然Vanilla小批量梯度下降法并不能保证较好的收敛性, 但是需要强调的是, 这也给我们留下了如下的一些挑战:
- 选择一个合适的学习率是困难的; 学习率太小会导致收敛的速度很慢, 学习率太大会妨碍收敛, 导致损失函数在最小值附近波动甚至偏离最小值
- 学习率调整试图在训练的过程中通过例如退火(annealing)的方法调整学习率, 即根据预定义的策略或者当相邻两代之间的下降值小于某个阀值时减小学习率; 然而, 策略和阀值需要预先设定好, 因此无法适应数据集的特点
- 此外, 对所有的参数更新使用同样的学习率; 如果数据是稀疏的, 同时, 特征的频率差异很大时, 我们也许不想以同样的学习率更新所有的参数, 对于出现次数较少的特征, 我们对其执行更大的学习率
- 高度非凸误差函数普遍出现在神经网络中, 在优化这类函数时, 另一个关键的挑战是使函数避免陷入无数次优的局部最小值; Dauphin等人指出出现这种困难实际上并不是来自局部最小值, 而是来自鞍点, 即那些在一个维度上是递增的, 而在另一个维度上是递减的; 这些鞍点通常被具有相同误差的点包围, 因为在任意维度上的梯度都近似为0, 所以SGD很难从这些鞍点中逃开
梯度下降优化算法
下面, 我们将列举一些算法, 这些算法被深度学习社区广泛用来处理前面提到的挑战; 我们不会讨论在实际中不适合在高维数据集中计算的算法, 例如二阶方法中的牛顿法
动量法
SGD很难通过陡谷, 即在一个维度上的表面弯曲程度远大于其他维度的区域, 这种情况通常出现在局部最优点附近; 在这种情况下, SGD摇摆地通过陡谷的斜坡, 同时, 沿着底部到局部最优点的路径上只是缓慢地前进, 这个过程如下图中的(a)所示
如上图(b)所示, 动量法是一种帮助SGD在相关方向上加速并抑制摇摆的一种方法; 动量法将历史步长的更新向量的一个分量\(\gamma\)增加到当前的更新向量中(部分实现中交换了公式中的符号)
$$ v_t = \gamma v_{t-1} + \eta\nabla_\theta J(\theta) $$
$$ \theta = \theta - v_t $$
动量项\gamma通常设置为0.9或者类似的值
从本质上说, 动量法, 就像我们从山上推下一个球, 球在滚下来的过程中累积动量, 变得越来越快(知道达到终极速度, 如果有空气阻力的存在, 则\(\gamma < 1\)); 同样的事情也发生在参数的更新过程中: 对于在梯度点处具有相同的方向的维度, 其动量项增大, 对于在梯度点处改变方向的维度, 其动量项减小; 因此, 我们可以得到更快的收敛的速度, 同时减少摇摆
更多关于:
- 梯度下降优化算法(Nesterov加速梯度下降法, Adagrad, Adadelta, RMSprop, Adam)
- 算法可视化
- 选择使用哪种优化算法?
- 并行和分布式SGD
- 优化SGD的其他策略
参考https://blog.csdn.net/google19890102/article/details/69942970

